

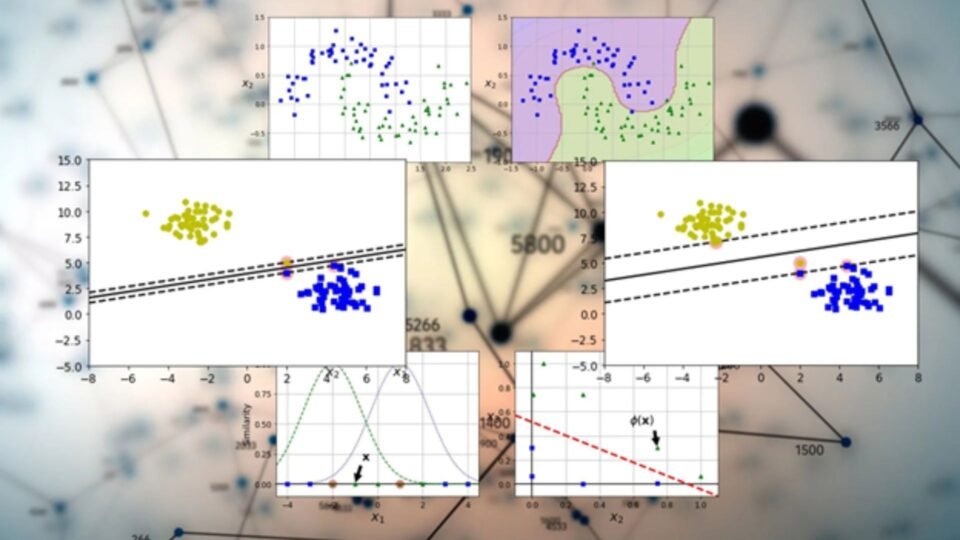
Support Vector Machines (SVMs) are a type of supervised machine learning algorithm used for classification and regression tasks. They are particularly effective for binary classification problems, but can also be extended to handle multi-class classification.
The main idea behind Support Vector Machine Algorithm is to find an optimal hyperplane that separates the data points of different classes with the maximum margin. The hyperplane is a decision boundary that separates the data into different classes based on their features.
The margin is the distance between the hyperplane and the closest data points from each class. The SVM algorithm aims to maximize this margin, as it is believed to lead to better generalization and improved performance on unseen data.
Advantages of SVMs:
- They can handle high-dimensional data effectively, even when the number of features exceeds the number of samples.
- SVMs are less prone to overfitting, as they try to maximize the margin, which encourages generalization.
- The use of kernel functions allows SVMs to capture complex relationships between the features by implicitly mapping the data to a higher-dimensional space.
Using SVMs For Data Sciences:
Support Vector Machines (SVMs) are a popular machine learning algorithm used in data science for classification and regression tasks. Here’s a step-by-step guide on how to use SVMs for data science:
- Data Preparation:
Start by preparing your data. Ensure that your dataset is labeled, meaning that each data point is associated with a corresponding class or target value. SVMs require numerical features, so if your dataset contains categorical variables, you’ll need to encode them appropriately (e.g., one-hot encoding or label encoding).
Additionally, normalize or standardize your numerical features to ensure they have similar scales.
- Splitting the Data:
Divide your dataset into training and testing sets. The training set will be used to train the SVM model, while the testing set will be used to evaluate its performance. Typically, an 80/20 or 70/30 split is used, but this can vary depending on the size of your dataset.
- Selecting the SVM Type:
Determine whether you need a classification or regression SVM. For classification tasks, SVMs use different kernels (linear, polynomial, radial basis function, etc.) to separate data points into different classes. For regression tasks, SVMs estimate a continuous function to predict numerical values.
- Model Training:
Train your SVM model using the training data. The process involves finding an optimal hyperplane that separates the data points of different classes with the largest margin. This is achieved by solving the optimization problem associated with SVMs.
- Hyperparameter Tuning:
SVMs have several hyperparameters that influence the model’s performance. Some important ones include the choice of kernel, regularization parameter (C) and kernel-specific parameters (e.g., gamma for the radial basis function kernel).
Use techniques like grid search or random search to explore different combinations of hyperparameters and find the best values based on cross-validation performance.
- Model Evaluation:
Evaluate your trained SVM model using the testing data. Calculate relevant evaluation metrics such as accuracy, precision, recall, F1-score or mean squared error (depending on the task). These metrics will provide insights into the model’s performance and its ability to generalize to unseen data.
- Model Optimization:
If your SVM model is not performing as expected, consider optimizing it further. You can try adjusting the hyperparameters, exploring different kernels, collecting more training data or applying feature engineering techniques to improve the model’s accuracy.
- Predictions:
Once your SVM model is trained and evaluated, you can use it to make predictions on new, unseen data. Transform the input data using the same preprocessing steps applied to the training data and then feed it into the trained SVM model to obtain predictions.
Model Deployment:
If you’re satisfied with the SVM model’s performance, you can deploy it to make predictions in real-world applications. Save the trained model to disk and load it when needed. Ensure that you also include the preprocessing steps required to transform new data before making predictions.
Conclusion:
Using SVMs in data science requires careful consideration of various steps, including data preprocessing, model training, hyperparameter tuning and evaluation. It’s essential to iterate through these steps, experiment with different approaches and continuously refine the model to achieve optimal performance.